
While most of the machines on the CERN cloud are configured using
Puppet with state stored in external databases or file stores, there are a few
machines where this has been difficult, especially for legacy applications.
Doing a regular snapshot of these machines would be a way of
protecting against failure scenarios such as hypervisor failure or disk
corruptions.
This could always be scripted by the project administrator using
the standard functions in the openstack client but this would also involve
setting up the schedules and the credentials externally to the cloud along with
appropriate skills for the project administrators. Since it is a common
request, the CERN cloud investigated how this could be done as part of the
standard cloud offering.
The approach that we have taken uses the Mistral project to execute
the appropriate workflows at a scheduled time. The CERN cloud is running a
mixture of OpenStack Newton and Ocata but we used the Mistral Pike release in
order to have the latest set of fixes such as in the cron triggers. With the
RDO packages coming out in the same week as the upstream release, this avoided
doing an upgrade later.
Mistral has a set of terms which explain the different parts of a
workflow (https://docs.openstack.org/mistral/latest/terminology).
The approach needed several steps
- Mistral tasks to define the steps
- Mistral workflows to provide the order to perform the
steps in
- Mistral cron triggers to execute the steps on schedule
Mistral Workflows
The Mistral workflows consist of a set of tasks and a process
which decides which task to execute next based on different branch criteria
such as success of a previous task or the value of some cloud properties.
Workflows can be private to the project, shared or public. By
making these scheduled snapshot workflows public, the cloud administrators can
improve the tasks incrementally and the cloud projects will receive the latest
version of the workflow next time they execute them. With the CERN gitlab based
continuous integration environment, the workflows are centrally maintained and
then pushed to the cloud when the test suites have completed successfully.
The following Mistral workflows were defined
instance_snapshot
Virtual machines can be snapshotted so that a copy of the virtual
machine is saved and can be used for recovery or cloning in future. The
instance_snapshot workflow performs this operation for both virtual machines
which have been booted from volume or locally.
|
Parameter
|
Description
|
Default
|
|
instance
|
The name of the instance to
be snapshot
|
Mandatory
|
|
pattern
|
The name of the snapshot to
store. The text ={0}= is replaced by the instance name and the text ={1}= is
replaced by the date in the format YYYYMMDDHHMM.
|
{0}_snapshot_{1}
|
|
max_snapshots
|
The number of snapshots to
keep. Older snapshots are cleaned from the store when new ones are created.
|
0 (i.e. keep all)
|
|
wait
|
Only complete the workflow
when the steps have been completed and the snapshot is stored in the image
storage
|
false
|
|
instance_stop
|
Shut the instance down
before snapshotting and boot it up afterwards.
|
false (i.e. do not stop the
instanc)
|
|
to_addr_success
|
e-mail address to send the
report if the workflow is successful
|
null (i.e. no mail sent)
|
|
to_addr_error
|
e-mail address to send the
report if the workflow failed
|
null (i.e. no mail sent)
|
The steps for this workflow are described in the detail in the
YAML/YAQL files at https://gitlab.cern.ch/cloud-infrastructure/mistral-workflows.
The operation is very fast with Ceph based boot-from-volumes since
the snapshot is done within Ceph. It can however take up to a minute for
locally booted VMs while the hypervisor is ensuring the complete disk contents
are available. The VM is resumed and the locally booted snapshot is then sent
to Glance in the background.
The high level steps are
· Identify server
· Stop instance if
requested by instance_stop
· If the VM is
locally booted
o Snapshot the
instance
o Clean up the
oldest image snapshot if over max_snapshots
· If the VM is
booted from volume
o Snapshot the
volume
o Cleanup oldest
volume snapshot if over max_snapshots
· Start instance
if requested by instance_stop
· If there is an
error and to_addr_error is set
o Send an e-mail
to to_addr_error
· If there is no
error and to_addr_success is set
o Send an e-mail
to to_addr_success
restore_clone_snapshot
For applications which are not highly available, a common
configuration is using a LanDB alias to a particular VM. In the event of a
failure, the VM can be cloned from a snapshot and the LanDB alias updated to
reflect the new endpoint location for the service. This workflow will create a
volume if the source instance is booted from volume. The workflow is called
restore_clone_snapshot.
The source instance needs to be still defined since information
such as the properties, flavor and availability zone are not included in the
snapshot and these are propagated by default.
|
Parameter
|
Description
|
Default
|
|
instance
|
The name of the
instance from which the snapshot will be cloned
|
Mandatory
|
|
Date
|
The date of the snapshot to
clone (either YYYYMMDD or YYYYMMDDHHMM)
|
Mandatory
|
|
pattern
|
The name of the snapshot to
clone. The text ={0}= is replaced by the instance name and the text ={1}= is
replaced by the date.
|
{0}_snapshot_{1}
|
|
clone_name
|
The name of the new
instance to be created
|
Mandatory
|
|
avz_name
|
The availability zone to
create the clone in.
|
Same as the source instance
|
|
flavor
|
The flavour for the cloned
instance
|
Same as the source instance
|
|
meta
|
The properties to copy to
the new instance
|
All properties are copied
from the source[1]
|
|
wait
|
Only complete the workflow
when the steps have been completed and the cloned VM is running
|
false
|
|
to_addr_success
|
e-mail address to send the
report if the workflow is successful
|
null (i.e. no mail sent)
|
|
to_addr_error
|
e-mail address to send the
report if the workflow failed
|
null (i.e. no mail sent)
|
Thus, cloning the machine timbfvlinux143 to timbfvclone143
requires running the workflow with the parameters
{“instance”: “timbfvlinux143”, “clone_name”: “timbfvclone143”,
“date”: “20170830” }
This results in
· A new volume
created from the snapshot timbfvlinux143_snapshot_20170830
· A new VM is
created called timbfvclone143 booted from the new volume
An instance clone can be run for VMs which are booted from volume
even when the hypervisor is not running. A machine can then be recovered from
it's current state using the procedure
· Instance
snapshot of original machine
· Instance clone
from that snapshot (using today's date)
· If DNS aliases
are used, the alias can then be updated to point to the new instance name
For Linux guests, the rename of the hostname to the clone name occurs
as the machine is booted. In the CERN environment, this took a few minutes to
create the new virtual machine and then up to 10 minutes to wait for the DNS
refresh.
For Windows guests, it may be necessary to refresh the Active
Directory information given the change of hostname.
restore_inplace_snapshot
In the event of an issue such as a bad upgrade, the administrator
may wish to roll back to the last snapshot. This can be done using the
restore_inplace_snapshot workflow.
This operation works for locally booted machines, maintains the IP
and MAC address but cannot be used if the hypervisor is down. It does not
currently work for boot from volume until the revert to snapshot (available in
Pike from https://specs.openstack.org/openstack/cinder-specs/specs/pike/cinder-volume-revert-by-snapshot.html) is in
production.
|
Parameter
|
Description
|
Default
|
|
instance
|
The name of the
instance from which the snapshot will be replaced
|
Mandatory
|
|
date
|
The date of the snapshot to
replace from (either YYYYMMDD or YYYYMMDDHHMM)
|
Mandatory
|
|
pattern
|
The name of the snapshot to
replace from. The text ={0}= is replaced by the instance name and the text
={1}= is replaced by the date.
|
{0}_snapshot_{1}
|
|
wait
|
Only complete the workflow
when the steps have been completed and the replaced VM is running
|
false
|
|
to_addr_success
|
e-mail address to send the
report if the workflow is successful
|
null (i.e. no mail sent)
|
|
to_addr_error
|
e-mail address to send the
report if the workflow failed
|
null (i.e. no mail sent)
|
Mistral Cron Triggers
Mistral has another nice
feature where it is able to run a workflow at regular intervals. Compared to
standard Unix cron, the Mistral cron triggers use Keystone trusts to save the
user token when the trigger is enabled. Thus, the execution is able to run
without needing the credentials such as a password or valid Kerberos token.
The steps are as follows
to create a cron trigger via Horizon or the CLI.
|
Parameter
|
Description
|
Example
|
|
Name
|
The name of the cron
trigger
|
Nightly Snapshot
|
|
Workflow ID
|
The name or UUID of the
workflow
|
instance_snapshot
|
|
Params
|
A JSON dictionary of the
parameters
|
{“instance”:
“timbfvlinux143”, “max_snapshots”: 5, “to_addr_error”: “theadmin@cern.ch”}
|
|
Pattern
|
A cron schedule pattern
according to http://en.wikipedia.org/wiki/Cron
|
* 5 * * * (i.e. run daily
at 5a.m.)
|
This will then execute
the instance snapshot at 5a.m. sending a mail to theadmin@cern.ch in the event of a failure of the snapshot. 5 past copies will be
kept.
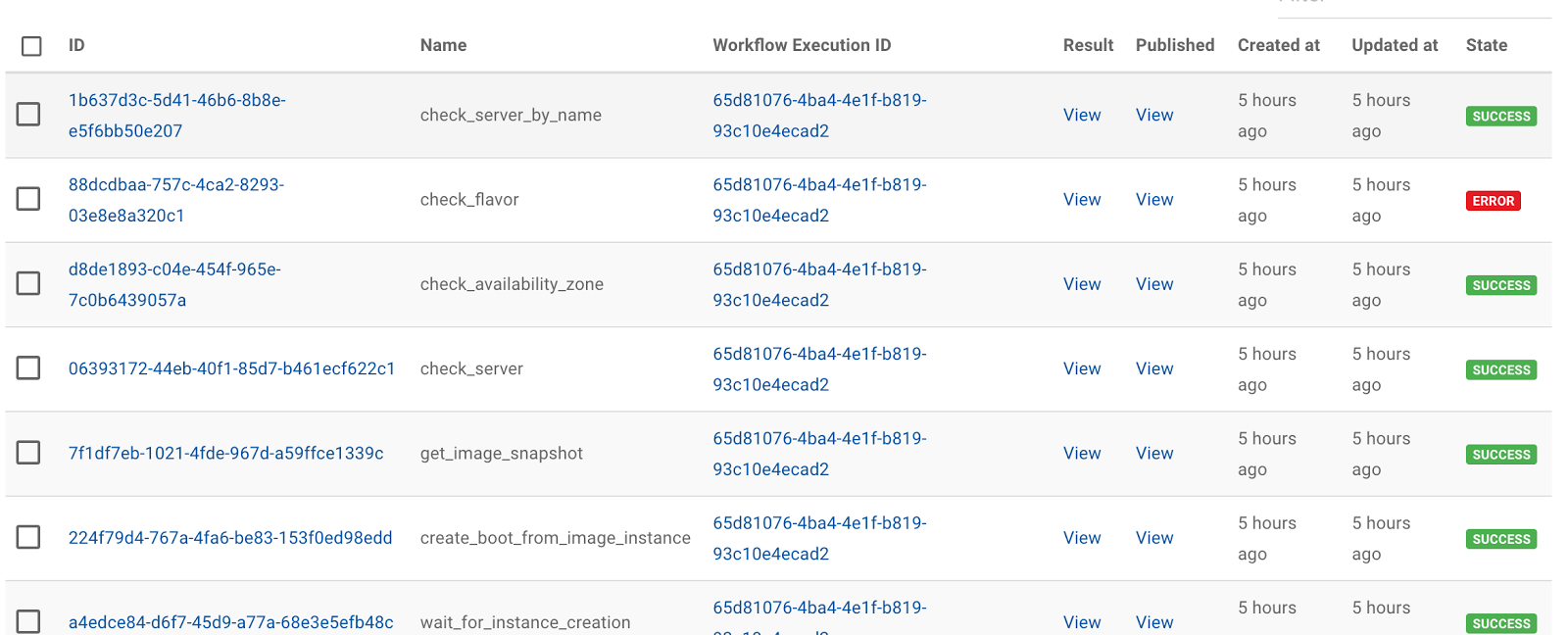
Mistral Executions
When Mistral runs a
workflow, it provides details of the steps executed, the timestamps for start
and end along with the results. Each step can be inspected individually as part
of debugging and root cause analysis in the event of failures.
The Horizon interface gives
an easy interface for selecting the failing tasks. There may be tasks reported
as ‘error’ but these steps can then have subsequent actions which succeed so an
error step may be a normal part of a successful task execution such as using a
default if no value can be found.
References
- Mistral
documentation https://docs.openstack.org/mistral/latest/
- YAQLuator for testing YAQL expressions - http://yaqluator.com/
- CERN Mistral Workflows source code - https://gitlab.cern.ch/cloud-infrastructure/mistral-workflows
- Computing at CERN - http://home.cern/about/computing
- CERN IT department – http://cern.ch/it
Credits
- Jose Castro Leon from the CERN IT cloud team did the
implementation of the Mistral project and the workflows described.