
CERN's OpenStack cloud runs the Juno release on mainly CentOS 7 hypervisors.
Along with previous tuning options described in this blog which can be used on Juno, a number of further improvements have been delivered in Kilo.
Since this release will be installed at CERN during the autumn, we had to configure standalone KVM configurations to test the latest features, in particular around NUMA and CPU pinning.
NUMA features have been appearing in more recent processors that means memory accesses are no longer uniform. Rather than a single large pool of memory accessed by the processors, the performance of the memory access varies according to whether the memory is local to the processor.

A typical case above is where VM 1 is running on CPU 1 and needs a page of memory to be allocated. It is important that the memory allocated by the underlying hypervisor is the fastest access possible for the VM1 to access in future. Thus, the guest VM kernel needs to be aware of the underlying memory architecture of the hypervisor.
The NUMA configuration of a machine can be checked using lscpu. This shows two NUMA nodes on CERN's standard server configurations (two processors with 8 physical cores and SMT enabled)
# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 62
Model name: Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz
Stepping: 4
CPU MHz: 2257.632
BogoMIPS: 5206.18
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 20480K
NUMA node0 CPU(s): 0-7,16-23
NUMA node1 CPU(s): 8-15,24-31
Thus, cores 0-7 and 16-23 are attached to the first NUMA node with the others on the second. The two ranges come from SMT. VMs however see a single NUMA node.
NUMA node0 CPU(s): 0-31
NUMA node0 CPU(s): 0-31
First Approach - numad
The VMs on the CERN cloud are distributed across different sizes. Since there is a mixture of VM sizes, NUMA has a correspondingly varied influence.

Linux provides the numad daemon which provides some automated balancing of NUMA workloads to move memory near to the processor where the thread is running.
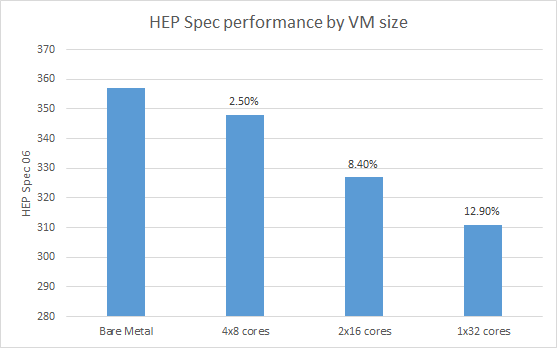
In the case of 8 core VMs, numad on the hypervisor provided a performance gain of 1.6%. However, the effects for larger VMs was much less significant. Looking at the performance for running 4x8 core VMs versus 1x32 core VM, there was significantly more overhead for the large VM case.

Second approach - expose NUMA to guest VM
This can be done using appropriate KVM directives. With OpenStack Kilo, these will be possible via the flavors extra specs and image properties. In the meanwhile, we configured the hypervisor with the following XML for libvirt.
<cpu mode='host-passthrough'>
<numa>
<cell id='0' cpus='0-7' memory='16777216'/>
<cell id='1' cpus='16-23' memory='16777216'/>
<cell id='2' cpus='8-15' memory='16777216'/>
<cell id='3' cpus='24-31' memory='16777216'/>
</numa>
</cpu>
In an ideal world, there would be two cells defined (0-7,16-23 and 8-15,24-31) but KVM currently does not support non-contiguous ranges on CentOS 7 [1]. The guests see the configuration as follows
# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 2
NUMA node(s): 4
Vendor ID: GenuineIntel
CPU family: 6
Model: 62
Model name: Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz
Stepping: 4
CPU MHz: 2593.750
BogoMIPS: 5187.50
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 4096K
NUMA node0 CPU(s): 0-7
NUMA node1 CPU(s): 8-15
NUMA node2 CPU(s): 16-23
NUMA node3 CPU(s): 24-31
With this approach and turning off numad on the hypervisor, the performance of the large VM improved by 9%.
We also investigated the numatune options but these did not produce a significant improvement.
Third Approach - Pinning CPUs
From the hypervisor's perspective, the virtual machine appears as a single process which needs to be scheduled on the available CPUs. While the NUMA configuration above means that memory access from the processor will tend to be local, the hypervisor may then choose to place the next scheduled clock tick on a different processor. While this is useful in the case of hypervisor over-commit, for a CPU bound application, this leads to less memory locality.
With Kilo, it will be possible to pin a virtual core to a physical one. The same was done using the hypervisor XML as for NUMA.
<cputune>
<vcpupin vcpu="0" cpuset="0"/>
<vcpupin vcpu="1" cpuset="1"/>
<vcpupin vcpu="2" cpuset="2"/>
<vcpupin vcpu="3" cpuset="3"/>
<vcpupin vcpu="4" cpuset="4"/>
<vcpupin vcpu="5" cpuset="5"/>
...
This will mean that the virtual core #1 is always run on the physical core #1.
Repeating the large VM test provided a further 3% performance improvement.
The exact topology has been set in a simple fashion. Further investigation on getting exact mappings between thread siblings is needed to get the most of out of the tuning.
The impact on smaller VMs (8 and 16 core) is also needing to be studied. Optimising for one use case has a risk that other scenarios may be affected. Custom configurations for particular topologies of VMs increases the operations effort to run a cloud at scale. While the changes should be positive, or at minimum neutral, this needs to be verified.
Summary
Exposing the NUMA nodes and using CPU pinning has reduced the large VM overhead with KVM from 12.9% to 3.5%. When the features are available in OpenStack Kilo, these can be deployed by setting up the appropriate flavors with the additional pinning and NUMA descriptions for the different hardware types so that large VMs can be run at a much lower overhead.
This work was in collaboration with Sean Crosby (University of Melbourne) and Arne Wiebalck and Ulrich Schwickerath (CERN).
- CPU topology - http://openstack-in-production.blogspot.fr/2015/08/openstack-cpu-topology-for-high.html
- CPU model selection - http://openstack-in-production.blogspot.fr/2015/08/cpu-model-selection-for-high-throughput.html
- KSM and EPT - http://openstack-in-production.blogspot.fr/2015/08/ept-and-ksm-for-high-throughput.html
Updates
[1] RHEV does support this with the later QEMU rather than the default in CentOS 7 (http://cbs.centos.org/repos/virt7-kvm-common-testing/x86_64/os/Packages/, version 2.1.2)
References
- Detailed presentation on the optimisations - https://indico.cern.ch/event/384358/contributions/909247/
- Red Hat's tuning guide - https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Virtualization_Tuning_and_Optimization_Guide/sect-Virtualization_Tuning_Optimization_Guide-NUMA-NUMA_and_libvirt.html
- Stephen Gordon's description of the Kilo features -http://redhatstackblog.redhat.com/2015/05/05/cpu-pinning-and-numa-topology-awareness-in-openstack-compute/
- NUMA memory architecture - http://frankdenneman.nl/2015/02/27/memory-deep-dive-numa-data-locality/
- OpenStack memory placement - https://wiki.openstack.org/wiki/VirtDriverGuestCPUMemoryPlacement
- Fedora work - http://bderzhavets.blogspot.fr/2015/07/cpu-pinning-and-numa-topology-on-rdo_31.html
Nice post.
ReplyDeleteAngular JS online training
Angular JS training
App V online training
App V training
Application packaging online training
Application packaging training
Blockchain online training
Blockchain training
C online training
C training
Data power online training
Data power training
Data Stage online training
I really liked your blog article.Really thank you! Really Cool.
ReplyDeleteSAP ABAP training
SSAP PP online training
data science training
teradata training
oracle bpm training
angular js training
Liên hệ Aivivu, đặt vé máy bay tham khảo
ReplyDeleteVé máy bay đi Mỹ
ve may bay my ve vietnam
bay từ đức về việt nam mấy tiếng
mua vé máy bay từ nhật về việt nam
vé máy bay từ hàn về Việt Nam
ve may bay tu canada ve viet nam
danh sách khách sạn cách ly
vé máy bay chuyên gia nước ngoài sang Việt Nam
me know if this okay with you. Thanks a lot!
ReplyDeleteMuleSoft training
MuleSoft online training